This is second in the series of articles I plan to write about my learnings of Building an AI product, defining evals, iterating through solutions and finally demonstrating impact on the customer & business. If you have not read the first article, start here.
Table of Contents
Open Table of Contents
First, why evals?
AI is non-deterministic but your product and customers who are using it need “reliability” in doing their tasks! Evals are a critical part of AI product development and Product Managers should be the internal champions of rigorous evals!
It is a systematic way to measure and communicate AI product quality to your customers and teams.
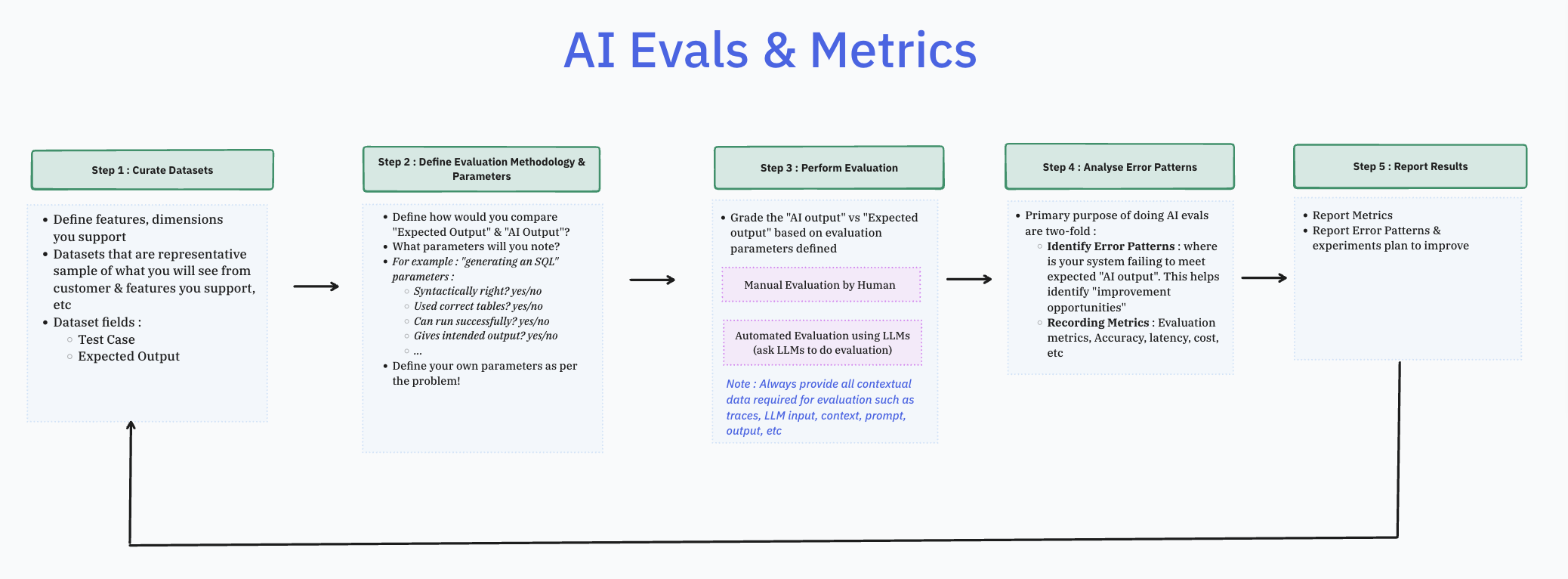
How to do Evals
- Step 1 : Curate your Datasets (Test cases, Expected output)
- Step 2 : Define your Evaluation Methodology & parameters :
- Define how will anyone compare (Ideal output vs AI output)
- Define Evaluation parameters
- What aggregated metrics you will convey from evaluation?
- Step 3 : Perform Evaluation
- Manual (human judge) - (start here!)
- Automated (LLM-as-a-judge) - (More on this topic later!)
- Step 4 : Analyse Error Patterns :
- Error Patterns : why test-cases failed and tag them
- LLM not getting all the context?
- Context not in right format?
- Customer inputs are not good!
- more…
- Error Patterns : why test-cases failed and tag them
- Step 6 : Report Evaluation Metrics
Example : How I did Evals for Developer Copilot, a coding agent
Feature : Conversational Developer Assistant
Feature description & how it works
Chat with Freddy AI developer assistant to generate code, fix errors, and get answers to your Freshworks app development questions. It uses typical RAG pipeline (Retrieval Augmented Features) on internally maintained knowledge base around developer platform.
How we did Evals
-
Step 1 : We created benchmark datasets
- I analysed 1000 prompts from production manually and created a dataset with :
- Identified Intent (debugging, generating feature code, generating frontend code, etc)
- Expected Output
- I analysed 1000 prompts from production manually and created a dataset with :
-
Step 2 : Defined evaluation methodology & parameters
- Methodology : Answer should contain “certain things” to be called a “accurate” answer. Each AI response will be scored “yes/no” on the list of criteria defined
- For each test-case in the dataset we defined multiple
- “Answer should include….”
- “Answer should include…”
- For example for a debugging intent to “fix an error:
”, Answer should include… - Root cause of the error :
- Code with Error Fixed : <this is how the fixed code template would look like…>
- Code should be syntactically correct javascript
- ….. (whatever you as a SME can define)
- Root cause of the error :
-
Step 3 : Define evaluation metrics
- Accuracy Baseline Measure :
- % of test-cases with >= 0.5 score i.e. This is a good response if you pass at-least half of the “answer should have criteria”
- Avg Accuracy Score :
- Overall avg accuracy score across the dataset
- These are just our defined metrics purely based on our evaluation methodology. Good product teams & companies are defining their Dataset & Evals. This allows them to iterate faster and replace LLMs, etc at will.
- Accuracy Baseline Measure :
-
Step 4 : Analyse Error Patterns
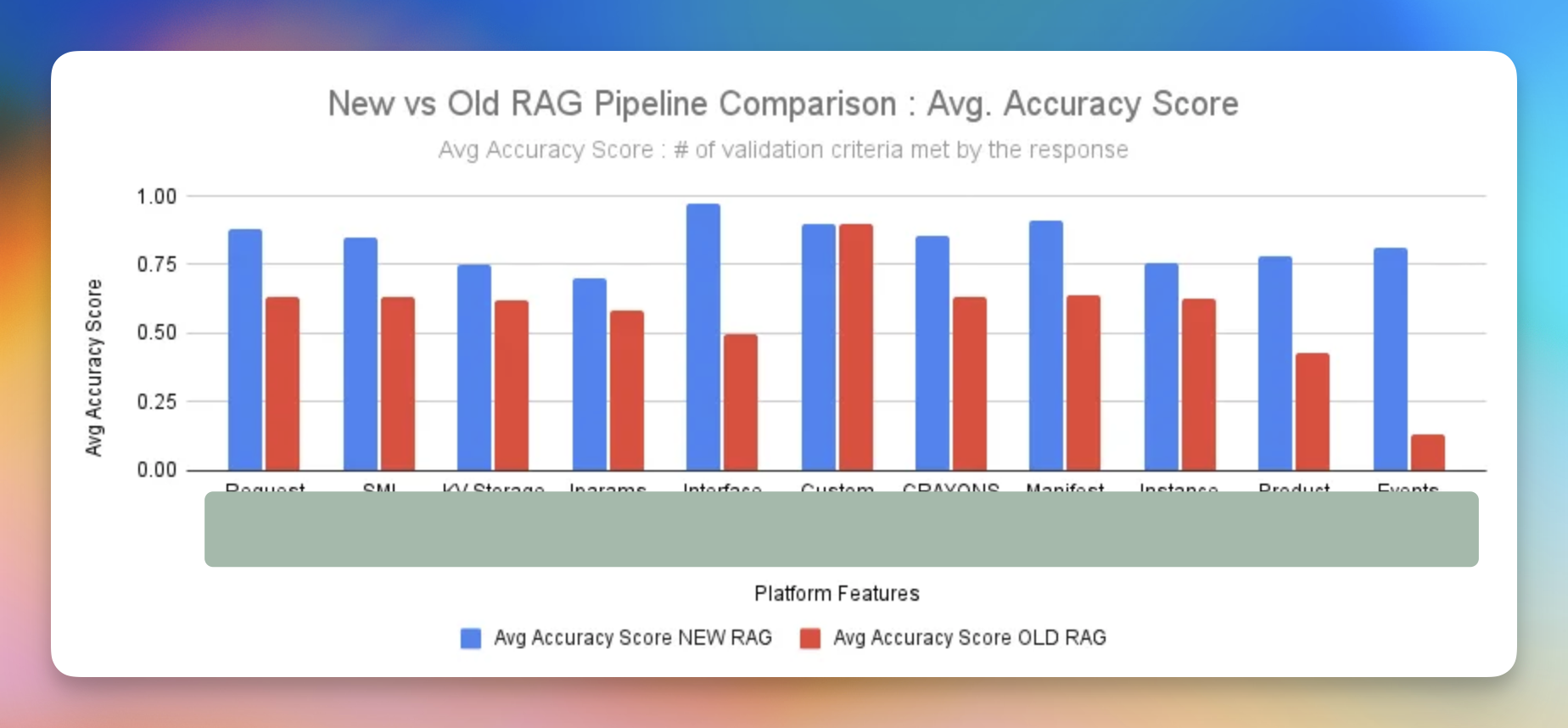
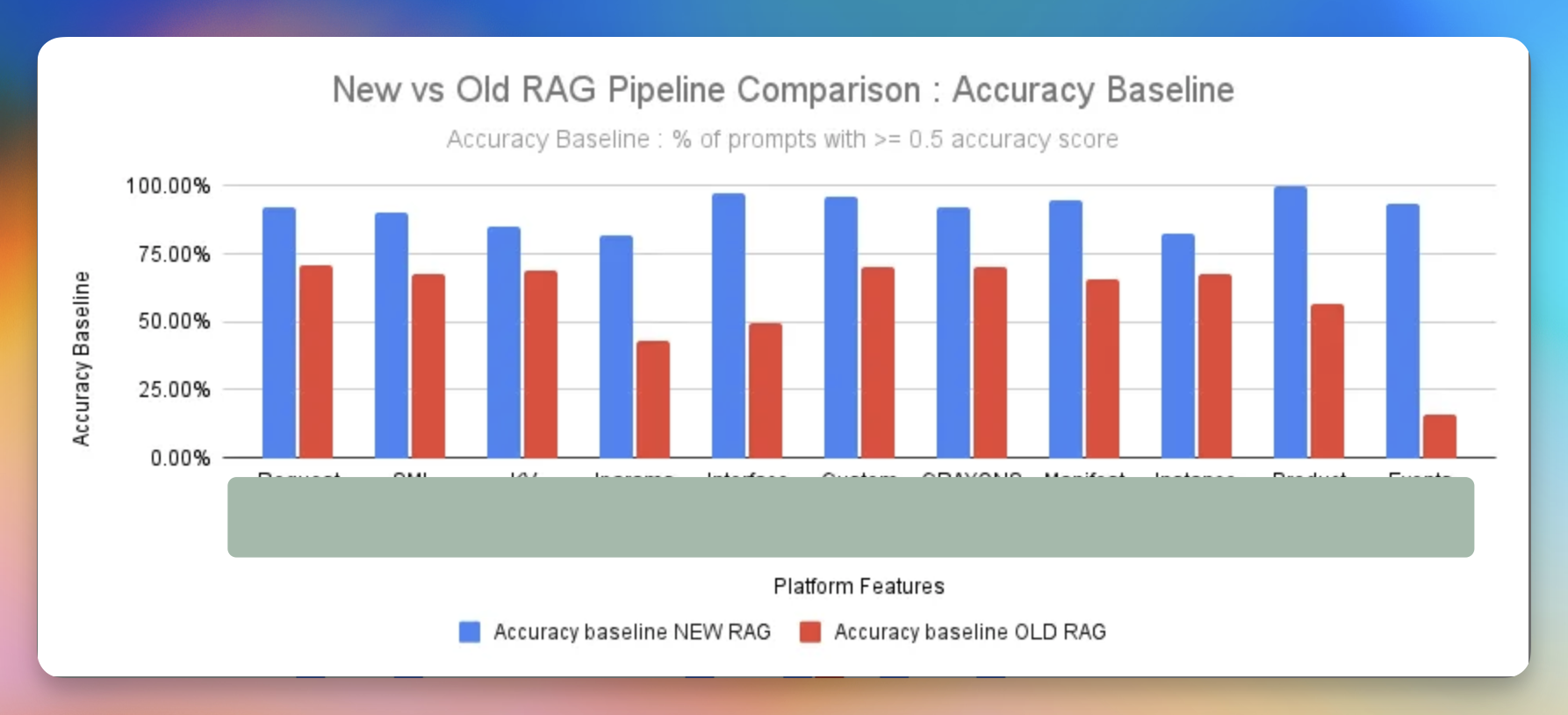
- Feature uses a typical RAG (Retrieval Augmented Generation pipeline), after analysis, we realised the biggest issues were in searching & fetching the “right context”.
- We had tonnes of experiments in tokenisation, query chunking, hybrid retrieval algorithms to improve context fetching which led to improves on the evals & eventually product metrics
-
Report the metrics
- Here are some recorded improvements we did by going from naive to advanced RAG pipeline.
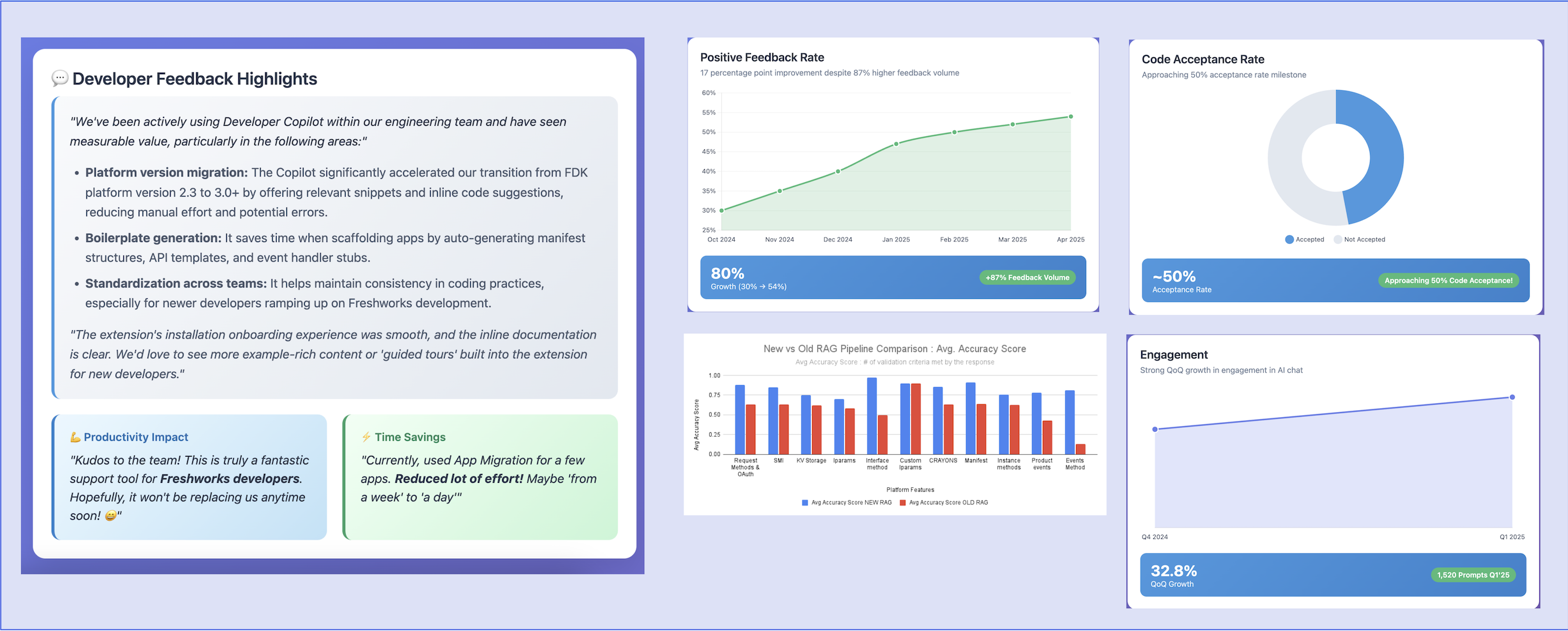
Impact - Developer Love ❤️❤️
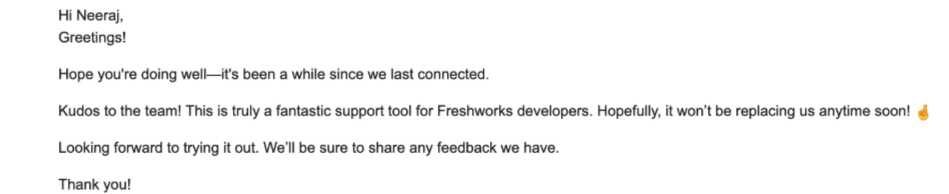
- Developers were praising productivity gains in development and the ability to migrate apps to new platform versions seamlessly with AI assistance
- “Positive feedback rate” almost doubled from 30% to 54% even while feedback volume jumped 87% > - indicating both higher satisfaction and broader adoption
- Continually improve “Response acceptance rate” - a critical milestone showing developers trust and actively adopt AI-generated suggestions
- Developer engagement accelerated 32.8% QoQ - reflecting sustained and growing usage patterns