AI Agent design is very different from traditional software development and Harness Engg. is at the frontend and centre of it. Building intelligent systems (thianks to LLMs) require orchestrating powerful LLMs and new types of primitives tools, skills, MCPs in an env. that let LLMs flourish!
No wonder, Both Openai and Anthropic has been very vocal about how to design harness for different use-cases esp. software development.
I have been building some side projects such as Leaf (an open source markdown reader app) and trying to use some of these concepts to test them!
YouTube walkthrough
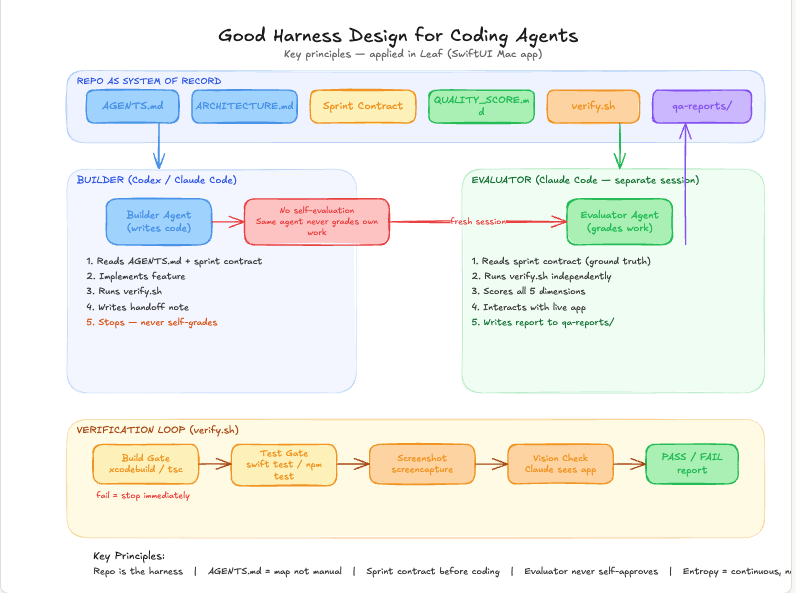
1. Repo as a system of record
The repo should not just store source files. It should act as the system of record for the entire development loop.
That means specs, tasks, implementation, tests, eval cases, and learnings should all sit close to the code. When the repo is the center of gravity, both humans and agents have a shared place to read from and write back to.
This matters because software development quickly becomes chaotic when intent is scattered across chat threads, docs, local notes, and half-remembered decisions. The repo creates a durable memory. It tells you:
- what the system is supposed to do
- what changed
- how it is verified
- what was learned while building it
Once you treat the repo as the record, you can build much stronger workflows on top of it.
2. Auto-evaluation loop
A harness should not depend on someone manually inspecting every change.
It should have an auto-evaluation loop that continuously checks whether the output is getting better or worse. This can include tests, linting, screenshots, benchmark checks, task-level evals, or product-specific acceptance checks.
The important bit is not any single eval. The important bit is the loop:
- make a change
- run evaluations automatically
- inspect failures
- refine the system
- repeat
This is what turns development from “generate code and hope” into an actual feedback system.
In AI-assisted development, this becomes even more important. Agents can produce a lot of output quickly, but speed without evaluation just means you can be wrong faster. The harness has to close that loop automatically.
3. Dedicated black-box evaluator agent
One of the most useful patterns is to have a dedicated black-box evaluator agent.
Its job is not to implement. Its job is to judge outcomes from the outside.
That separation matters. The builder agent is usually too close to the solution. It knows what it intended to do, which makes it easier to miss gaps. A black-box evaluator looks at the system the way a user, tester, or reviewer would:
- given this input, what actually happened?
- does the output match the spec?
- did quality regress?
- what failed, exactly?
This agent becomes even more useful when connected to the repo and the evaluation loop. It can read the spec, run the system, compare behavior against expectations, and write back structured findings. Over time, that creates a much more reliable development process.